


















无论是数据通讯技术的演进、互联网技术的革新、还是视觉呈现的升级,都是得益于更强大的计算、更大容量更安全的存储以及更高效的网络。基于InfiniBand网络为基础的集群架构方案,不仅可以提供更高带宽的网络服务,同时也降低了网络传输负载对计算资源的消耗,降低了延时,又完美地将HPC与数据中心融合,构建了元宇宙发展的基石。
InfiniBand 网络架构的奥秘
从InfiniBand解决方案的全景图中,有网卡、交换机、线缆、网络端到端的硬件设备,还有DPU、网关设备,从而不仅构建了完备的数据中心的网络设备,而且还打通了与广域网同城应用的节点,实现了硬件完备的网络传输解决方案,有两点值得一提:

一是盒式交换机,1U 40口的200G交换机,可以提升20%的交换能力。
二是InfiniBand提供了业界新概念的DPU网卡,实现在业务负载上的卸载和隔离,做到了端到端的网络管理与维护,最大化兼容老旧设备,可以让设备无缝连接到高性能的InfiniBand网络。而在这些硬件的基础之上,开创性的构建了网络计算这一新兴概念,实现在交换机上做计算,同时结合SHIELD、SHARP、GPURDMADirect等功能之后,使得InfiniBand网络更加的智能和高效。
InfiniBand 是如何实现加速计算的?
讲到计算,不太了解RDMA应用的人们可能会疑惑,一个负责传输的网络是如何实现对计算的加速呢?RDMA就是这样一种技术,在通信两端的服务器内实现数据的直接传输,整个数据的操作CPU是完全不会介入,不仅降低了CPU的开销,而且也使得CPU不会成为数据传输的瓶颈,使得数据传输可以向200G、400G乃至1TB的数据的演进。

从图上我们可以看出,对于一个普通的服务器当没有使用RDMA技术的时候,由于CPU要负责大量的协议的开销处理,使得有47%的资源工作在Kernel态下,而只有大概50%的资源用于程序的计算,限制了整个服务器的应用扩展。当如果我们使用RDMA技术之后,使得大量的消耗CPU资源的数据面完全被卸载在网卡上,我们就可以能够控制在Kernel的资源在CPU的12%,将用户态的CPU资源实现翻倍。这样不仅将整个传输的性能提高,同时腾出来的CPU的资源又可以能够部署更多的计算的负载,实现了整个带宽的提升的同时,又增加了业务的部署,提高了整个服务器的利用效率。
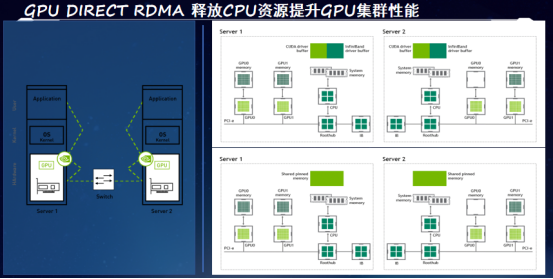
另外,如何对GPU实现加速呢?
现在随着AI技术的快速普及,GPU的应用也变得越来越重要,而且在GPU上由于有成千上万的核要做计算,对数据传输的需求就会更大。在CPU服务器正在普遍向100G过渡的时候,GPU的服务器200G的网络已经成为标配,并且我们正在向400G乃至800G的网络过渡。因此GPU对网络传输的需求会更为迫切。
解决方案除了需要像RDMA这样的技术之外,还需要进一步扩展在网络数据面上的制约,让GPU全速运行。在标准的GPU服务器的架构上,GPU是以PCIe的方式和CPU进行互联的,在这种架构下就决定了GPU在服务器数据传输时,所有的数据都要经过CPU。
要解决这个问题,需要GPU Direct RDMA的技术,该技术可以实现让GPU和网卡直接bypass掉CPU,实现网卡和GPU之间的数据直连。这样只需要一步的数据拷贝,就可以让处于发送端GPU的数据从它的显存中直接一步跳到目的端的GPU的显存内,实现数据的快速拷贝。简化了流程,降低了时延,实现对GPU应用的加速的效果。
使用了GPU Direct RDMA技术之后,其对AI集群可以实现90%的时延的节省,4K以上报文大小的message传输的I/O带宽实现了十倍的性能的提升。同时在这样网络性能大幅提升的前提下,对AI集群的并行计算的任务实现了一倍以上的性能改进的效果,大幅提高了AI集群的效能,改善了投入产出比。
以上我们从网卡的角度上阐述了InfiniBand如何机遇性的加速CPU和GPU计算,当然,那作为网络中最为关键的交换机,InfiniBand是如何加速网络计算的?这里需要提到InfiniBand的应用SHARP了。
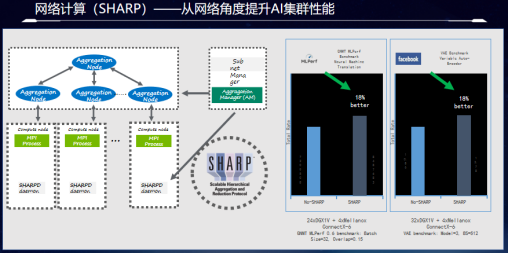
我们知道AI训练过程中有着大量的AllReduce的操作,直白地讲,就是负责分布式计算的GPU要同时更新自己的数据到不同的计算GPU上,这样的话在这种框架下就决定了数据要反复地进行网络,保持数据在各个GPU上的同步。并且AllReduce的计算类型无非是求和异或求最值等简单但是计算频繁的操作。我们知道了这样的计算模式之后,就可以设想把交换机变成一个计算节点,将所有的GPU的数据统一汇集到交换机上进行计算,并且统一分发到各个GPU上。这样由于交换机的转发带宽远大于服务器,如此的架构不仅没有数据传输的瓶颈,而且在数据网络中的流转只需要一次就可以完成所有的计算过程,大大简化了计算过程,降低了时延,消除了瓶颈。
从上面的图例可以看出,在几十台DGX的服务器集群规模上使用了网络计算功能之后,整体集群完成训练的任务的性能提升了18%,这就意味着当使用了InfiniBand网络的集群的时候,交换机不仅完成了高性能的数据传输,同时还完成了近两成的计算任务,为客户提高了性能的同时,节省了大量的服务器投入成本。
结语
通过InfiniBand的网络重新解构集群,将计算单元、存储单元立化成池,用InfiniBand作为整个集群的背板总线,高效地将其互联起来,为软件定义集群奠定了硬件的基础。这样,高性能集群就变成了一台超高性能的服务器,可以根据各种任务的负载特性的不同,灵活配置计算与存储资源,最大限度地满足效率的同时,还能有更高的性能表现。并且在未来集群扩容时,可以根据真实的情况需要,定向扩容所需的资源,提高集群的弹性。而这一切,都需要建立在高可靠、高带宽、低延时的网络上。